10 Downloading Data onto Hazel
When your research requires pulling data from public databases, repositories, or the web, you need to think through three decisions: where to run the download, what tool to use, and where on Hazel the data will live once it arrives. This chapter walks through each of these in turn.
10.1 Downloading from a VCL
Hazel’s compute nodes do not have outbound internet access — you cannot run a download from inside a SLURM job. Downloads must happen from a node that does: either the Hazel login node or an NC State Virtual Computing Lab (VCL) machine.
The login node is a shared resource. For small files or quick downloads (a few hundred megabytes or less), using the login node is acceptable. For large datasets or anything that will take more than a few minutes, use a VCL machine instead to avoid impacting other users.
The NC State VCL provides on-demand virtual machines with full internet access and access to Hazel storage. It is the recommended environment for all but the smallest downloads.
10.1.1 Reserving a VCL
- In a web browser, navigate to vcl.ncsu.edu, log in with your Unity ID credentials, and click Make a Reservation.
- Click the New Reservation box and select
HPC (RHEL 9 64 bit VM)from the drop down box. In this window you can also select how long the VCL will be active for, or schedule the VCL for later. Click Create Reservation
- After the reservation has finished Pending…, click Connect! for different connection options.
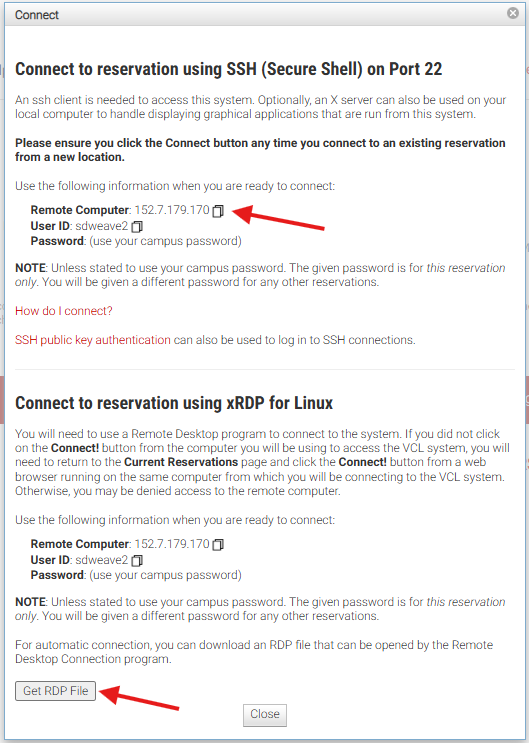
- SSH into the VCL from your local terminal
$ ssh [UnityID]@ip_addresss- Alernatively, download the RDP file by clicking Get RDP File and open it up. A window will promp you for your Unity ID credentials. This will open up a remote desktop, where the terminal connects automatically to hazel.
Because the VCL environment mounts Hazel storage directly, you can download files straight into your Hazel directories — there is no extra copy step needed. Use the same paths you would from the login node. Anything downloaded to /rs1/researchers/ or scratch from a VCL session is immediately available on Hazel.
VCLs exist for 1 hour by default and are available for up to 10 hours. Make sure you give your VCL session enough time to download your data.
10.2 Choosing a Download Tool
Once connected to the VCL, you can now download your data.
The two most common command-line tools for downloading files are wget and curl. Both are available on Hazel and on VCL machines. The table below summarizes when to reach for each.
| Situation | Recommended tool |
|---|---|
| Standard HTTP/HTTPS download | wget |
| URL that redirects before serving the file | curl -L |
| FTP download | Either; curl handles FTP cleanly |
| Resuming an interrupted download | Both (wget -c / curl -C -) |
| Downloading a list of URLs from a file | wget -i urls.txt |
When in doubt, wget is slightly simpler for one-off downloads; curl is more flexible for scripting or for servers that issue HTTP redirects.
10.3 Downloading with wget
wget fetches a file at a given URL and saves it to the current directory by default.
$ wget https://example.com/data/genome.fasta.gz10.3.1 Key flags
| Flag | What it does |
|---|---|
-O [filename] |
Save with a custom filename |
-P [directory] |
Save to a specific directory instead of the current one |
-c |
Resume an interrupted download |
-q |
Quiet mode — suppress progress output (useful in scripts) |
--progress=bar |
Show a progress bar instead of the default dot output |
-i [file] |
Download all URLs listed in a text file, one per line |
Save to a specific directory with a custom filename:
$ wget -O hg38.fna.gz -P /rs1/researchers/[letter]/[UnityID]/data/ \
https://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/000/001/405/GCA_000001405.15_GRCh38/GRCh38_major_release_seqs_for_alignment_pipelines/GCA_000001405.15_GRCh38_no_alt_analysis_set.fna.gzDownload a list of files from a text file:
$ cat urls.txt
https://example.com/sample1.fastq.gz
https://example.com/sample2.fastq.gz
https://example.com/sample3.fastq.gz
$ wget -i urls.txt -P /rs1/researchers/[letter]/[UnityID]/data/Resume a failed download:
$ wget -c https://example.com/data/large_file.tar.gzSome servers do not support resumable downloads. If wget -c restarts from the beginning rather than continuing, the server does not support range requests — you will need to let the download complete uninterrupted.
10.4 Downloading with curl
curl is a more flexible alternative to wget. By default it prints file contents to your terminal, so you almost always need an output flag.
$ curl -O https://example.com/data/genome.fasta.gz # save with the URL's filename
$ curl -o my_genome.fasta.gz https://example.com/data/genome.fasta.gz # save with a custom name10.4.1 Key flags
| Flag | What it does |
|---|---|
-O |
Save with the filename from the URL |
-o [filename] |
Save with a custom filename |
-L |
Follow HTTP redirects |
-C - |
Resume an interrupted download |
--ftp-pasv |
Use passive FTP mode (often needed behind firewalls) |
--progress-bar |
Show a simple progress bar |
Always include -L when using curl. Many data portals (NCBI, EBI, etc.) serve files via an HTTP redirect, and without -L you will download the redirect response rather than the file itself.
Follow redirects and save to the current directory:
$ curl -L -O https://ftp.ebi.ac.uk/pub/databases/reference/example_db.tar.gzResume a failed download:
$ curl -L -C - -O https://example.com/data/large_file.tar.gz10.5 Storage Considerations
Before downloading a large dataset, confirm you have enough space in the destination directory.
Check available space on a filesystem:
$ df -h /rs1/researchers/[letter]/[UnityID]/Check the size of existing files and directories:
$ du -sh *When choosing where to put downloaded data, keep Hazel’s storage tiers in mind (see HPC Terminology for a full overview):
/rs1/researchers/— persistent, backed-up storage. The right home for raw data, reference genomes, and anything you cannot easily re-download./share/$GROUP/$USER/(scratch space) — faster, but not backed up and subject to automatic purge policies.
Scratch storage on Hazel is automatically purged on a rolling schedule. If you download data to scratch, move it to /rs1/researchers/ promptly — or it may be deleted before you can use it.